I love APIs. They’re an amazing source of data for all kinds of creative projects.
But what if a website doesn’t provide an official API?
Can you still collect some data programmatically on a regular basis?
If you want to transform (almost) any public-facing website into an API, you can leverage the power of Python, using one of the scraping packages developed by the community.
If you need to interact with the page (fill out a form for instance), you’ll use Selenium. For the purpose of this article, we’ll use a simpler package, which works perfectly fine for most use cases: BeautifulSoup (bs4).
The first requirement is of course to have Python installed on your machine and pick your favourite IDE (I use PyCharm). If you’re new to Python, you can read my detailed tutorial explaining how to install it on your machine.
I’ll be using a Jupyter Notebook on Kaggle, which I will share at the end of this article. That’s a great way to run Python code in the cloud, step by step.
In the first cell of my notebook, I’m installing the bs4 package, in a persistent way, in my Kaggle workspace. This will enable me to have bs4 available for further sessions using the same notebook (otherwise, you have to re-install bs4 to use your script).
!pip install bs4 --target=/kaggle/working/mysitepackagesI run the code in the cell, then I can replace it by the import command and run the cell again. If there’s no error message, we’re good to go.
We just have to import another package (we can do it in the same cell & re-run it), which doesn’t require any further installation: requests. That’s the package you will always use to connect either to a public API or to call your own API using bs4 or another method. For the purpose of this demo, we’ll also import a built-in package to display the current date.
from bs4 import BeautifulSoup
import requests
from datetime import dateHow to get the data for the 10 Best Selling fiction books on Amazon?
Let’s say that we want to get the Best Selling fiction books on Kindle, which you can find on https://www.amazon.com/charts/mostsold/fiction
Let’s first connect to the web page.
#declaring the URL
url = "https://www.amazon.com/charts/mostsold/fiction"
# declare browser headers
headers = {'Accept-Language': "fr,en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"}
#getting the full content of the page
page = requests.get(url, headers = headers)
#parsing the HTML
soup = BeautifulSoup(page.content, "html.parser")In the next cell, we can print our “soup” (= the html content of the page)
print(soup)Here’s the kind of content you can expect. A slightly indigestible soup 😉
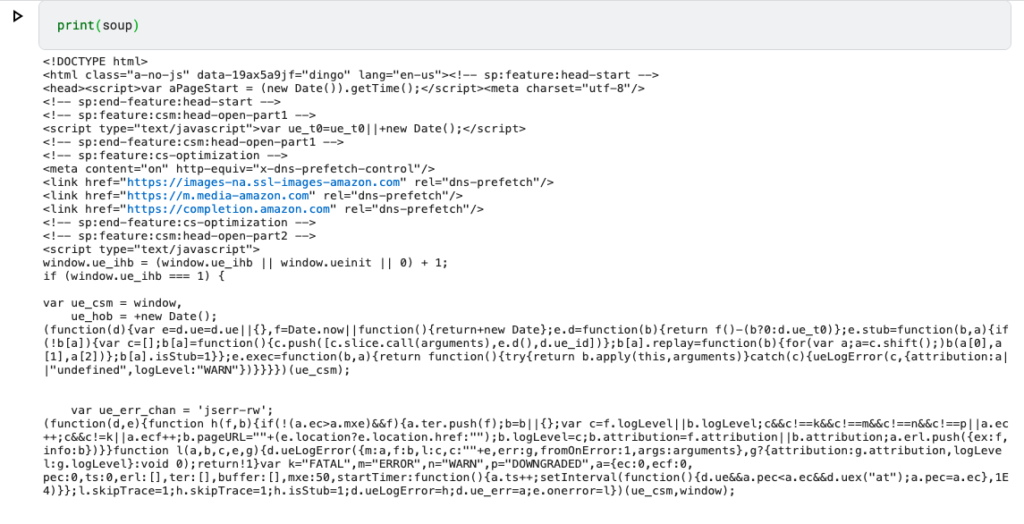
Now comes the fun part. We have to figure out how to get the data for those books.
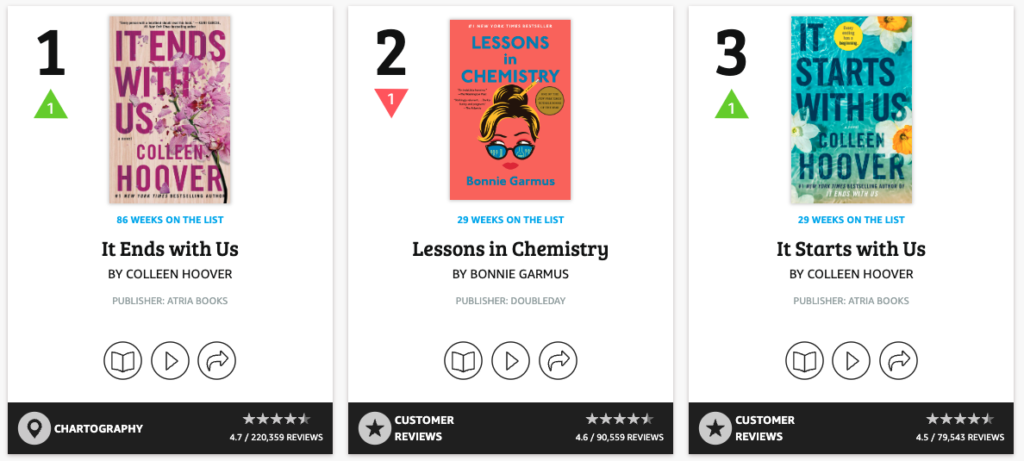
Head over to your Chrome browser and INSPECT a relevant element on the page.
That’s the kind of code you’ll see in the Elements tab of your Developer Tools.
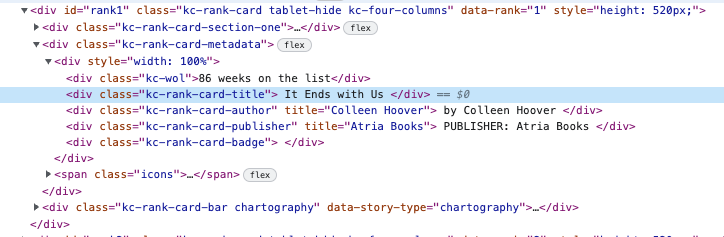
You might have noticed the id=”rank1″ of the DIV containing the information.
Let’s try to access it.

number_one_book = soup.find(id="rank1")
Let’s print “number_one_track” in the next cell.
print(number_one_book)We get the code for all the info about the #1 Best Selling fiction book on Amazon Kindle.
It’s still pretty indigestible… 🤢
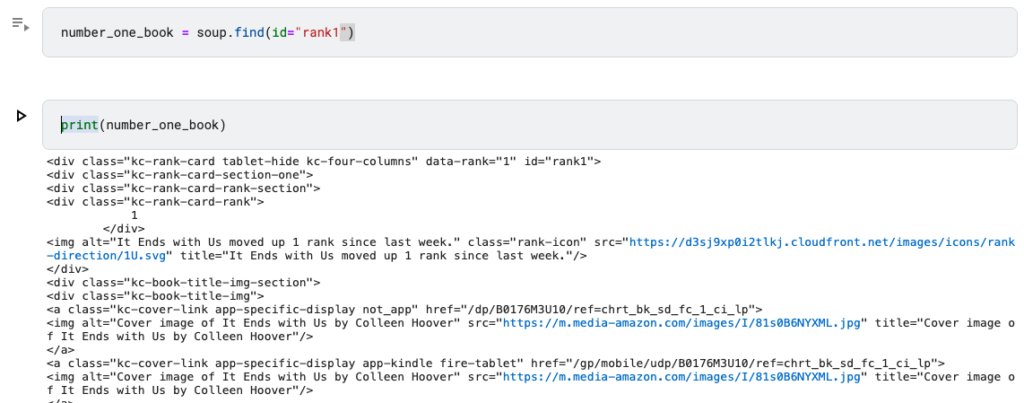
Now we have to locate the TITLE and the AUTHOR in the code. We’ll also find the PUBLISHER.
<div class="kc-rank-card-title">
It Ends with Us
</div>
<div class="kc-rank-card-author" title="Colleen Hoover">
by Colleen Hoover
</div>
<div class="kc-rank-card-publisher" title="Atria Books">
PUBLISHER: Atria BooksThat was easy.
So let’s write some code to focus on those 3 pieces of information.
number_one_book_title = soup.find(id="rank1").find(class_="kc-rank-card-title")You’ve noticed how I chained two .find() commands, to find the rank1 div id and the kc-rank-card-title class. Take note of the underscore after “class” (class_=”target-class”).
Let’s print this out, narrowing down to the text (.text), removing any white spaces (.strip( )).
print(number_one_book_title.text.strip())
#prints out:
It Ends with UsPerfect. Now let’s do the same for the author & the publisher and compute today’s date in a readable format. We will also adapt the code for the title extraction to get the clean text string.
number_one_book_title = soup.find(id="rank1").find(class_="kc-rank-card-title").text.strip()
number_one_book_author = soup.find(id="rank1").find(class_="kc-rank-card-author").text.strip()
number_one_book_publisher = soup.find(id="rank1").find(class_="kc-rank-card-publisher").text.strip()
today = date.today()
# dd/mm/YY
d1 = today.strftime("%d/%m/%Y")We can also get the image of the cover and of course the link to the ebook, which I will build using the slug (the end of the URL) found in the code.
number_one_book_cover = soup.find(id="rank1").find(class_="kc-cover-link").find("img").get("src")You have noticed how I chained multiple commands (find, find, find, get).
This will give me: https://m.media-amazon.com/images/I/81s0B6NYXML.jpg
number_one_book_slug = soup.find(id="rank1").find(class_="kc-cover-link").get("href")
number_one_book_url = "https://amazon.com" + number_one_book_slugThe full URL will be: https://amazon.com/dp/B0176M3U10/ref=chrt_bk_sd_fc_1_ci_lp
Now we can build a full output by concatenating the data.
We’ll wrap the info in HTML to show the image.
widget = f'<div style = "border: solid 1px black; text-align: center; padding: 10px"><p><span>{d1} - Number One Fiction Book On Amazon</span><br><b>{number_one_book_title}</b><br><span>{number_one_book_author}</span><br><span>{number_one_book_publisher}</span><br><br><span><a href={number_one_book_url} style="padding: 0.5em 1em; background-color: blue; color: white; text-decoration: none;">Buy the book</a></span><br></p><a href="{number_one_book_url}"><img src={number_one_book_cover} alt="{number_one_book_title}" width=100px></a></div>'👉 If I print out the result of this widget (print(widget)) and copy-paste it into a HTML block on this WordPress site, here’s the result:
01/02/2023 – Number One Fiction Book On Amazon
It Ends with Us
by Colleen Hoover
PUBLISHER: Atria Books
Buy the book

Now let’s imagine that we want the Top 10 of the best selling fiction books.
We won’t create a widget for the list (we could) but we’ll print out the results, along with the links to the books.
We have noticed that each book card has a rank{number} class. So, if we want to get the 10 best selling books, we can proceed this way:
print(f"10 Best Selling fiction books on Amazon - date: {d1}")
print("---------------------------------------------------------")
print("")
rank = 1
while rank <= 10:
book_title = soup.find(id=f"rank{rank}").find(class_="kc-rank-card-title").text.strip()
book_author = soup.find(id=f"rank{rank}").find(class_="kc-rank-card-author").text.strip()
book_publisher = soup.find(id=f"rank{rank}").find(class_="kc-rank-card-publisher").text.strip()
book_slug = soup.find(id=f"rank{rank}").find(class_="kc-cover-link").get("href")
book_url = "https://amazon.com" + book_slug
print(f"Ranked {rank}: {book_title} - {book_author} | {book_publisher}. Link: {book_url}")
rank += 1👉 Note: I used f strings (f”{}”) to mix text and variables: f”text{variable}”
If I run this cell, I get the following output:
10 Best Selling fiction books on Amazon - date: 01/02/2023 --------------------------------------------------------- Ranked 1: It Ends with Us - by Colleen Hoover | PUBLISHER: Atria Books. Link: https://amazon.com/dp/B0176M3U10/ref=chrt_bk_sd_fc_1_ci_lp Ranked 2: Lessons in Chemistry - by Bonnie Garmus | PUBLISHER: Doubleday. Link: https://amazon.com/dp/B098PW8NP8/ref=chrt_bk_sd_fc_2_ci_lp Ranked 3: It Starts with Us - by Colleen Hoover | PUBLISHER: Atria Books. Link: https://amazon.com/dp/1668001225/ref=chrt_bk_sd_fc_3_ci_lp Ranked 4: Verity - by Colleen Hoover | PUBLISHER: Hoover Ink, Inc.. Link: https://amazon.com/dp/1791392792/ref=chrt_bk_sd_fc_4_ci_lp Ranked 5: Remarkably Bright Creatures - by Shelby Van Pelt | PUBLISHER: HarperAudio. Link: https://amazon.com/dp/B09DTGQHKJ/ref=chrt_bk_sd_fc_5_ci_lp Ranked 6: Tomorrow, and Tomorrow, and Tomorrow - by Gabrielle Zevin | PUBLISHER: Knopf. Link: https://amazon.com/dp/B09JBCGQB8/ref=chrt_bk_sd_fc_6_ci_lp Ranked 7: The Housemaid - by Freida McFadden | PUBLISHER: Bookouture. Link: https://amazon.com/dp/B09TWSRMCB/ref=chrt_bk_sd_fc_7_ci_lp Ranked 8: Demon Copperhead - by Barbara Kingsolver | PUBLISHER: Harper. Link: https://amazon.com/dp/B09QH6C42C/ref=chrt_bk_sd_fc_8_ci_lp Ranked 9: The House at the End of the World - by Dean Koontz | PUBLISHER: Brilliance Audio. Link: https://amazon.com/dp/B0B3F6FR6T/ref=chrt_bk_sd_fc_9_ci_lp Ranked 10: Reminders of Him - by Colleen Hoover | PUBLISHER: Montlake. Link: https://amazon.com/dp/B0976V6YSL/ref=chrt_bk_sd_fc_10_ci_lp
Mixing this technique with the tutorial I wrote about connecting Python to Google Sheets, you can store the data in a table for further processing.
👉 As promised, here’s the link to the public Jupyter notebook on Kaggle.
Have fun building your own personal APIs with Python and BeautifulSoup!
 Subscribe to my weekly newsletter packed with tips & tricks around AI, SEO, coding and smart automations
Subscribe to my weekly newsletter packed with tips & tricks around AI, SEO, coding and smart automations